
To store and query information, we looked at databases this week.
This is a good and important question. In many cases, you actually do not need anything more complicated that files in folders to store your "data". Databases are often more complex to set up and maintain than plain files, so being mindful of why you're using them and what you're gaining Even databases usually do eventually their data to files on the filesystem (you are just shielded from that). The main reasons to use a database instead of files:
If you don't care about these use cases, you may not need a database.
There are a few families of databases, all of which present different ideas around how to organize and query data. Within each kind family are a number of actual databases you can use in your projects.
Examples MySQL, SQLite, Postgres
Also known as RDBMS (Relational Database Management System), or Table databases, this is one of oldest ideas around how to organize data. For many people the word "database" means "relational database" and nothing else. The idea is that you organize data into tables with a fixed set of columns, and every row is a new piece of data. Each column has a descriptive name and specifies what type of data it accepts. The decision of what tables to use and what columns they should have is called the scheme and it describes the "shape" of the database. For example, a table of friends might have the following schema:
Friends
| name (string) | height (int) | birthday (date) |
This specifies that a Friend has a name, which is a string, a height, which is an integer, and a birthday which is a date. Different databases will support different types of data, and date as a datatype is quite common.
Populating the database could look like:
| name (string) | height (int) | birthday (date) | | "Ramsey" | 170 | 04/09 | | "Billy" | 175 | 06/12 | | "Sally" | 180 | 01/20 | | "Ahmad" | 155 | 02/02 |
Some things that are easy to do:
Some things that are hard to do:
Tables are "joined" using foreign keys, which are entries in a row that refer to IDs in another table. Sometimes intermediate tables are used to join two tables.
The language you insert or query data with is called the Structured Query Language. Like everything else in this family, it is quite old and there is a lot of writing available on it. Every different database will implement SQL a little differently, but it is technically standardized.
There is quite a bit more to it, including mathematical operations you can apply to your tables to make certain guarantees about the structure of your data. Youtube tutorials do a decent job of getting a bit deeper, and I found this one to be OK. Studying how other systems organize their data is also helpful. Here's Wikipedia's schema:
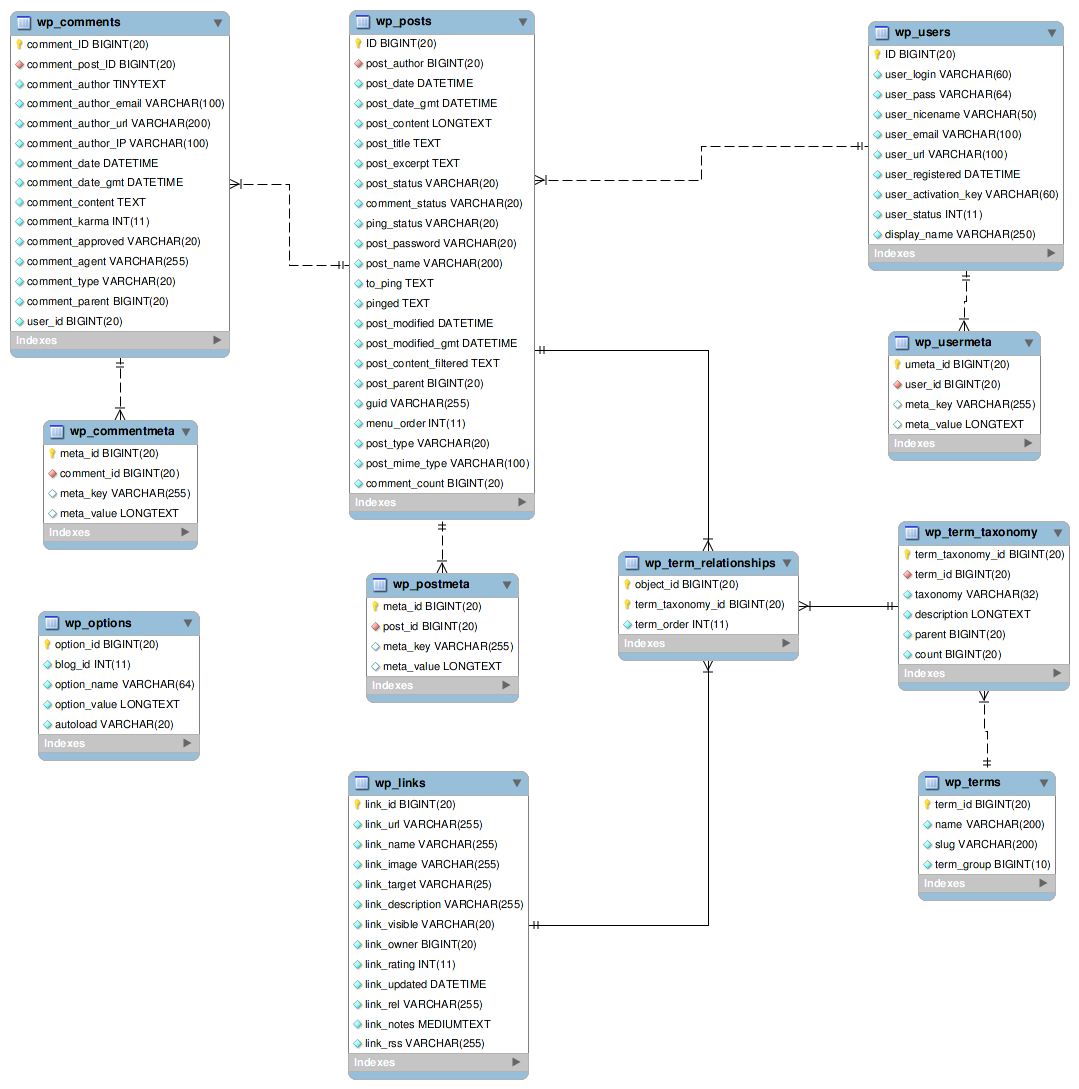
And Wordpress's:
Here, data is represented as a graph, with nodes and edges between them. They are much less mainstream, but suitable for datasets where "connectivity" is important. They're also good at modeling many-to-many relationships, where relational databases might require many intermediate tables.
Neo4j is fairly robust and well supported, and their videos provide a good inroduction to this family
Data is stored as a collection of documents, which can be thought of as JSON documents. They don't have a particular order or relationship to each other, and each document can have its own content, i.e. there usually isn't a schema in place. Document stores are good for data who's structure is unknown and might even change over time, but enforcing rules about data, preventing errors, and optimization becomes harder.
If you're thinking of storing data as a bunch of JSON files in a folder, you might want to consider a document store.
MongoDB has a free online set of courses if you want to explore that route, and Amazon's DynamoDB is well documented and supported as well.
Examples Redis, Riak, memcached
At their simplest, key value stores associate keys (names) with values and nothing else. That is, you can say "the key foo now has the value bar" and if you ask the database later "what is the value of foo?" it will respond with bar.
This simplicity allows for very fast operation, and key-value stores (especially memcached) get used for fast temporary storage. Some databases like Redis offer data structures on top of simple values, meaning your values can be lists and hash maps beyond numbers and strings.
They also tend to be easy to sey up, so for many use cases a simple key-value store is all you actually need. The try redis page is a great way to get a feel for these systems.
A common icon for databases you will see around is a sequence of stacked cylinders

This comes from classic high capacity storage hardware that often took the form of memory platters.

This hardware included technology as old as drum memory, but even as recently as a few years ago computers used mechanical hard dives with internal magnetic memory platters.
